ConcurrentHashMap 的绝妙设计
HashMap
HashMap 用作键值对存储,时间复杂度接近O(1)。
底层数据结构
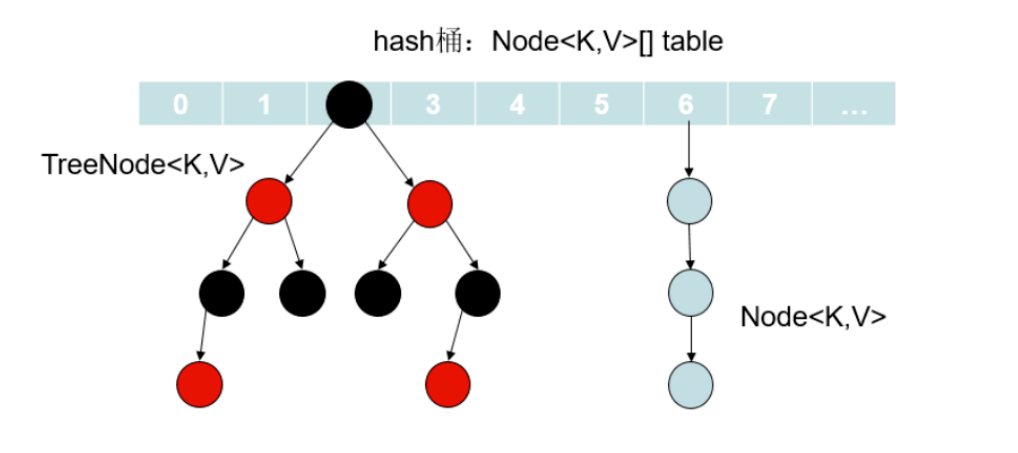
底层数据结构由“数组+链表组成”,数组是HashMap的主体,链表是为了解决哈希冲突(拉链法)而存在的。
链表过长会严重影响HashMap的性能,红黑树搜索时间复杂度是O(logn),链表是O(n),JDK1.8之后引红黑树。
当达到一定条件,链表和红黑树会进行转换:
- 当链表长度超过8时,且数组长度超过64会转为红黑树
- 若数组长度小于64,会先进行数组扩容,而不是转换成红黑树
红黑树增减元素需要进行左旋右旋,变色,这些操作来保持平衡,提高查找效率同时也会增加修改时间,链表元素未到阀值时使用链表。
寻址(key -> 数组下标)
HashMap 底层数据结构为数组,如何将key映射到对应数组下标存储位置?
最直接的方法,使用key的hashcode值,对数组长度取余,得到数组下标。
在 HashMap 中:
- key的hash值算法为
h ^ (h >>> 16),h为key的hashCode()值,通过异或一下当数组长度较小时让hash高位也参与运算,让元素更好的散列 - 将对数组长度取余,优化为效率更高的位运算
keyHash & (数组长度 - 1),(当数组长度为2的N次方与取余算法keyHash % 数组长度结果相同,所以HashMap底层数组初始、扩容后长度都为2^n)。
1 | /** |
626 | if ((p = tab[i = (n - 1) & hash]) == null) |
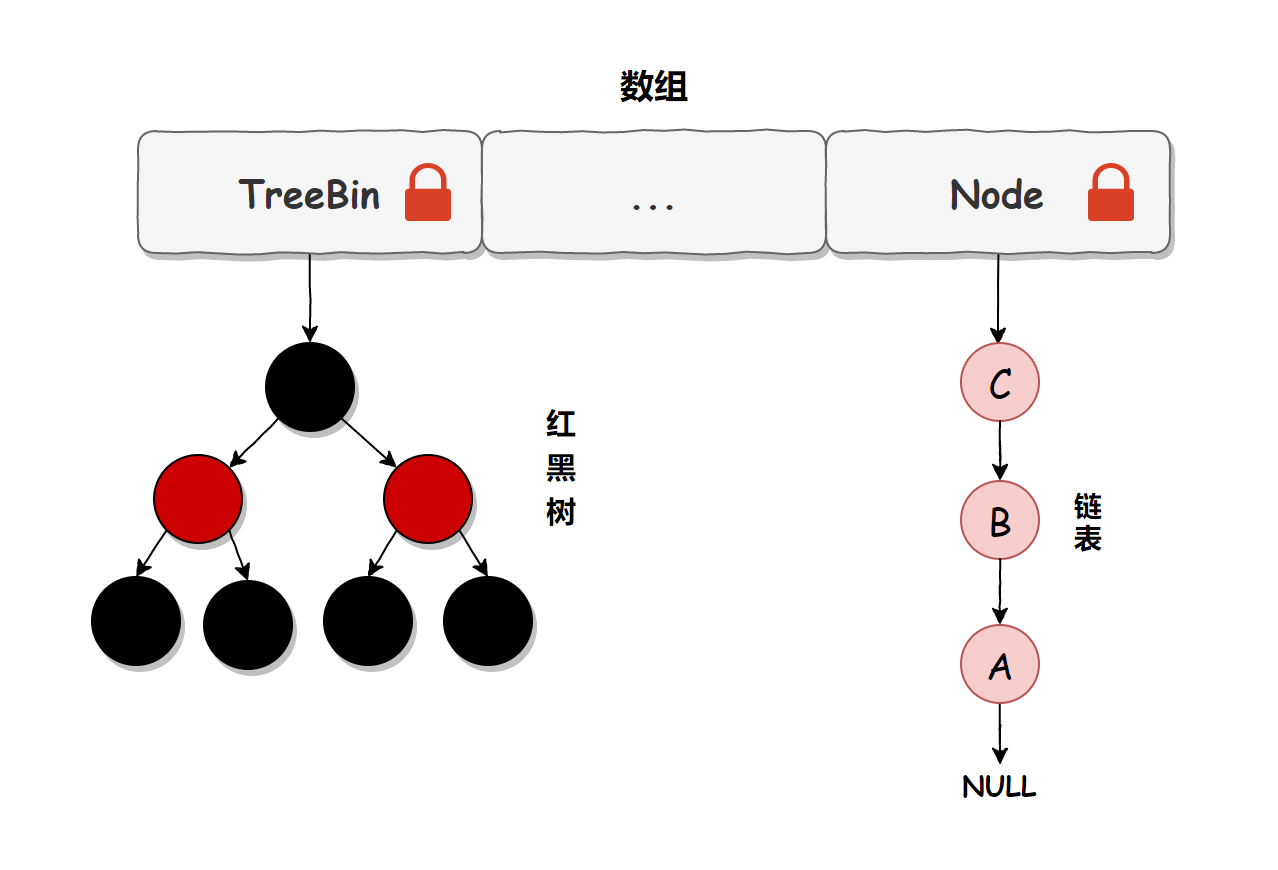
ConcurrentHashMap
HashMap 是线程不安全的,线程安全类 HashTable 只是简单的在方法上加锁实现线程安全,全部串行化,效率低下。
ConcurrentHashMap 底层结构基本上和 HashMap 一样,采用了 (数组 + 链表 + 红黑树)
ConcurrentHashMap 如何提高并发效率:
- 理想状态下,硬件CPU核数越多,则程序的并行执行效率越高,而在程序中必须被串行执行的部分越多,处理器无法对其进行加速执行效率比越低
- ConcurrentHash 通过分段锁、CAS乐观锁等手段减小锁粒度,优化并发性能
分段锁
CAS
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
Related Articles